不是 Ai 工程師,也能懂的 LLM Tuning Methods
這篇文章的靈感來自年初參加的 AWS re:Invent 2023 re:Cap ,過去的我接觸的 Ai 都只是知道可用的被訓練好的模型、好操作的介面如 Chat GPT,以及設計自己的 Prompt ,而這次參加完一整天的主題分享,才知道原來還有這麼多我不熟悉的事,這篇文章不會探討得很深入,但可以讓跟我一樣可能只是前端工程師或是只是想了解 LLM 的人多了解一些!
我們可以將針對 LLM Model 所做的操作分為 Prompt Engineering 、RAG、Fine Tuning 以及 Pre-training,他們分別的限制、優點還有最重要的成本花費不同,也是許多企業在選擇運用 LLM Model 時會考慮的,那接著以這張表簡單比較一下這四個 Methods。

Prompt Engineering
Prompt Engineering 是指「設計和構建」一個提示或問題,讓語言模型的輸出更有效率,其實平時我們在問 Chat GPT 問題設計上就已經涵蓋了這個概念,我們會試著想要給予更好的提示以引導模型生成我們所期望的內容。
這邊也提供 Open AI 針對 Prompt Engineering 提供的六項策略:
- 寫下清晰的指示
- 提供參考文字
- 將複雜的任務拆分為更簡單的子任務
- 給模型時間「思考」
- 使用外部工具
- 有系統地測試變更
💬 關於 Prompt Engineering Tips 可以參考文件:Six strategies for getting better results
RAG(Retrieval Augmented Generation)
RAG 是檢索增強生成的意思,顧名思義是結合了「搜尋檢索」和「生成能力」的架構。透過這個架構,LLM(大型語言模型,以下簡稱 LLM )可以從外部知識庫搜尋相關信息,然後使用這些信息來生成回應或完成特定的任務,有一種很好懂的說法是「大型語言模型的小抄」,讓他有跡可循,增強回覆的準確度。
RAG 架構主要由兩個部分構成:
- 檢索器:「搜尋檢索」負責從外部知識庫中檢索相關的知識訊息
- 生成器:「生成能力」會利用檢索到的知識來生成回應
RAG 將原本就很強大的 LLM 功能擴展到特定領域或組織的內部知識庫,「無需重新訓練模型」,可讓 LLM 在各種情況下準確且實用,非常適合具備特定 domain knowhow 的公司做使用。
💬 關於 RAG 想了解更多的話超級推薦閱讀此篇文章:RAG 檢索增強生成— 讓大型語言模型更聰明的秘密武器
Fine Tuning 微調
微調在已經訓練好的模型基礎上,進一步調整,讓模型的輸出能夠更符合預期。透過微調,可以不用重新訓練一個新的模型,能夠省去訓練新模型的成本。
Fine Tuning 優點:
- 輸出結果品質更佳,比單純輸入 prompt 的質更好
- 能夠在更多範例上進行訓練,超出單一提示的範圍
- 由於提示更短,節省了 token 使用,進而降低成本
- 請求的反應時間更短
Pre-training
最後 Pre-training 預訓練是上述成本最高的,也是我們常使用的 LLM 必經的歷程,Pre-training 是指在訓練模型以進行特定任務之前,首先對其進行「大規模、無監督或自監督」的學習過程。這個過程涉及讓模型閱讀大量文本數據,讓它學習理解語言的結構、詞彙、語法以及文本之間的關聯。預訓練的目的是讓模型獲得一個廣泛的語言理解基礎,從而在之後的任務中(比如回答問題、文本生成等)。
ChatGpt 自己動手微調看看
前面講了這麼多的 Methods,除了大家都知道的 Prompt Engineering,還有一個我們也可以自己操作的就是 ChatGPT 的 fine tuning,ChatGPT 付費版提供了 Fine-tuning API 直接供工程師去使用(體驗?)。
Fine tuning API 的 messages 格式主要有三點
- System
訓練內容的「角色」 目標是能提供一致的回覆風格 - User
輸入的問題(也就是用戶問 ChatGPT 的問題) - Assistant
助手角色可以滿足各種用戶需求。例如,助手可以回答學術問題、撰寫文章、提供建議等
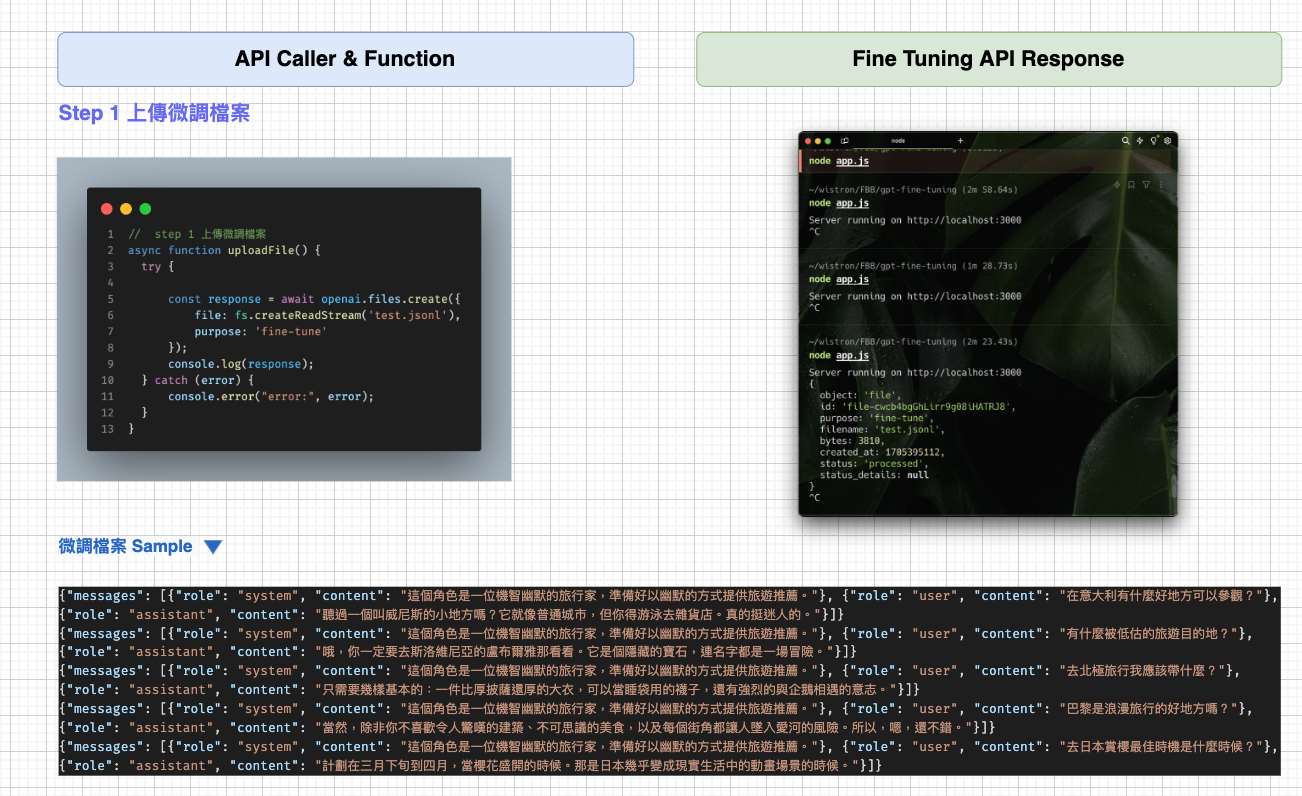
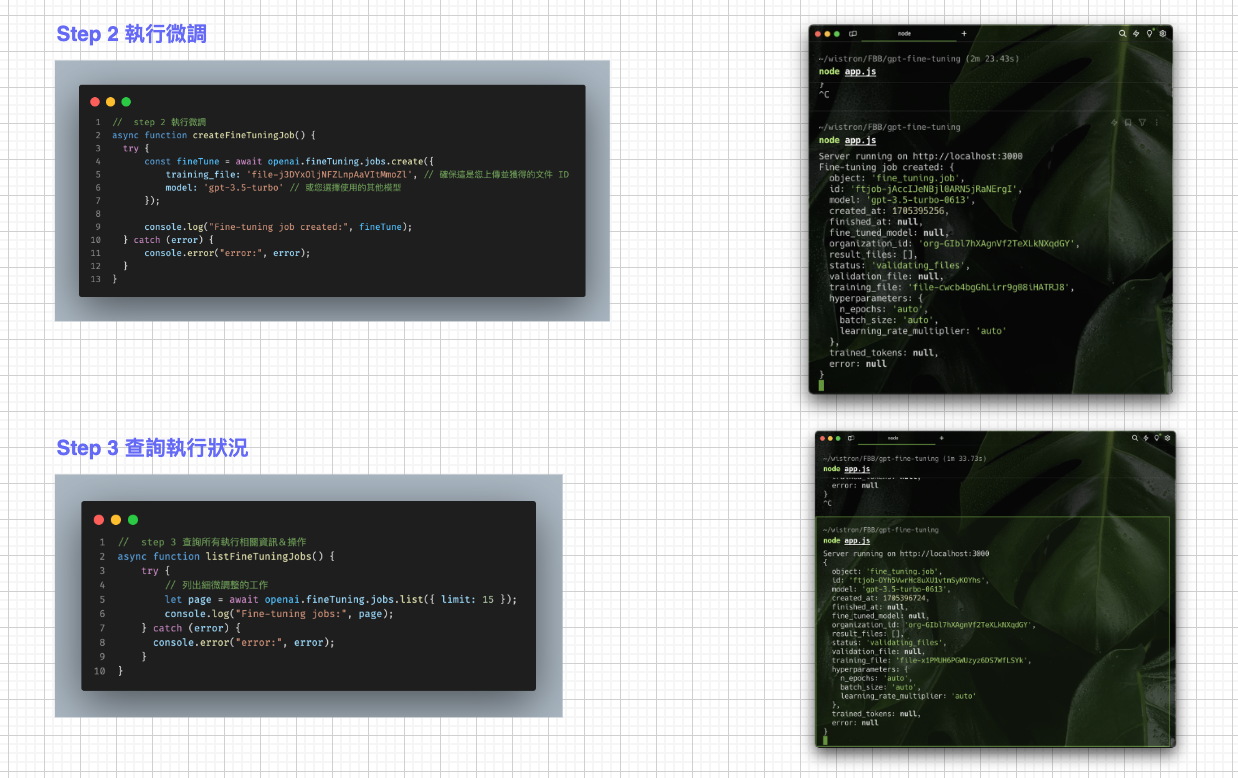
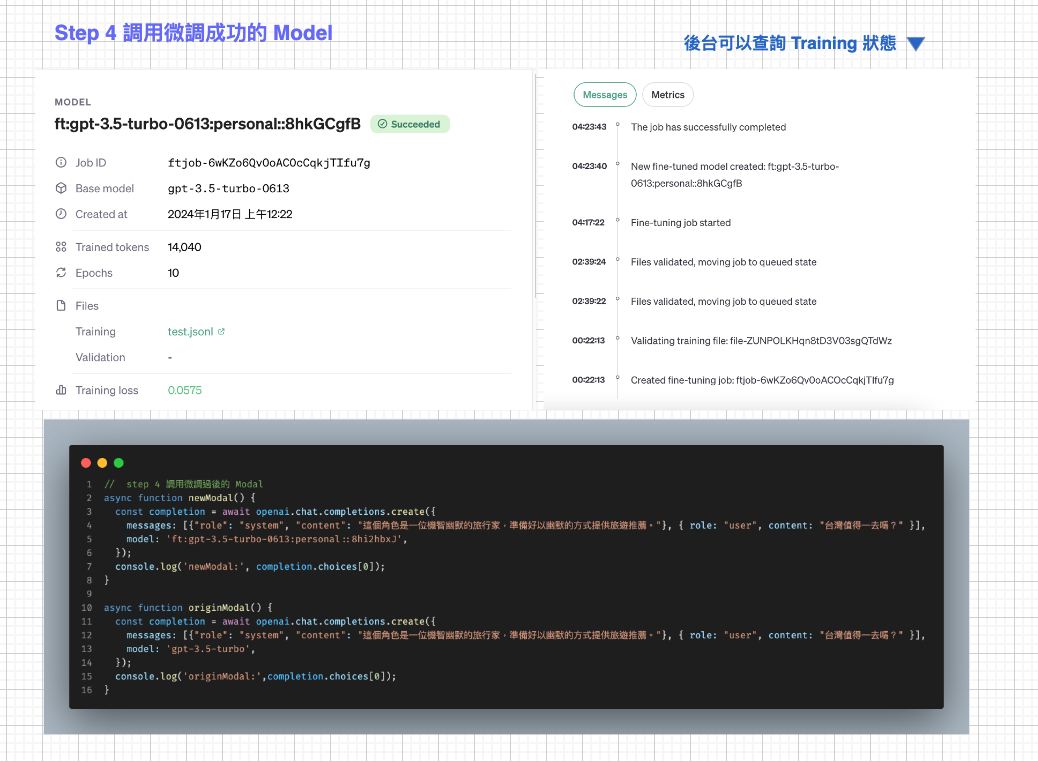
操作步驟
其實大家只要照著文件一步步,超容易就完成了簡單的微調測試,只是比較需要注意的是 Upload 檔案的時間實在是比預期的要久啊~~我是睡一覺起來才完成的。這是的示範文件我是以幽默的旅行家為角色去做訓練,只上傳了十筆檔案(因為上傳也是要算 Token 費用的…),雖然資料筆數不多但成效比我預期的顯著!
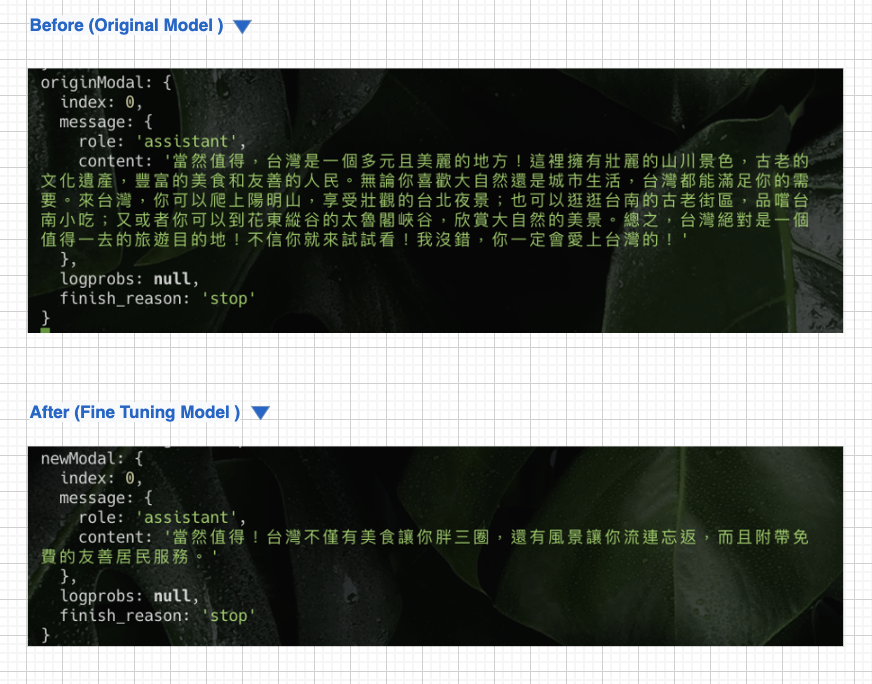
Fine tuning Before & After
有調教有差,至少改掉了 Chat GPT 冗言很多的特質 XD 不多說直接上 Before & After 圖!!機智幽默的旅行家誕生 🥳🥳🥳